




Introduction
In Part I of the SSAS Tabular vs. SSAS Multidimensional – Which One Do I Choose? series, we began to set the stage for looking at 5 high level considerations to answer this question. The considerations are:
- Scalability
- Performance
- Time to Develop
- Complex Business Problems
- Learning Curve
In this post, we will contemplate the Scalability and Performance aspects by comparing and contrasting SSAS Tabular and SSAS Multidimensional in these areas.
Scalability
One of the first important things we need to discuss to help us make an informed decision on SSAS Tabular vs Multidimensional is:
- Amount of data
- Server resources
- Disk space
Amount of Data
It is really important to understand not only how much data we are bringing in today, but what volume of data will we be bringing into the model in the future as well. One way to analyze this is after your initial import, you may want to ask yourself some additional questions:
- How often will I be refreshing the data?
- What is the growth of that data?
- How many rows are being added per day?
- The system I am working off of, is there a possibility that system will be expanded in the next 6 months to a year?
The key here is to think a little down the road, not just what is happening today.
Server Resources
Some important questions to ask and research when sizing a server or to determine what server resources are available:
- What are the processor capabilities?
- How much RAM is available on the server? Emphasis here…because Tabular is “in memory”.
- What type of disk space do we have available?
Tabular
There is a MSDN Article available for Hardware Sizing Tabular Solutions that provides information and guidance for estimating the hardware requirements needed to support workloads for a Analysis Services tabular solution.
Multidimensional
There is a MSDN Article available for Requirements and Considerations Analysis Services Deployment that provides information and guidance regarding underlying hardware, topology, and other characteristics for an Analysis Services multidimensional solution.
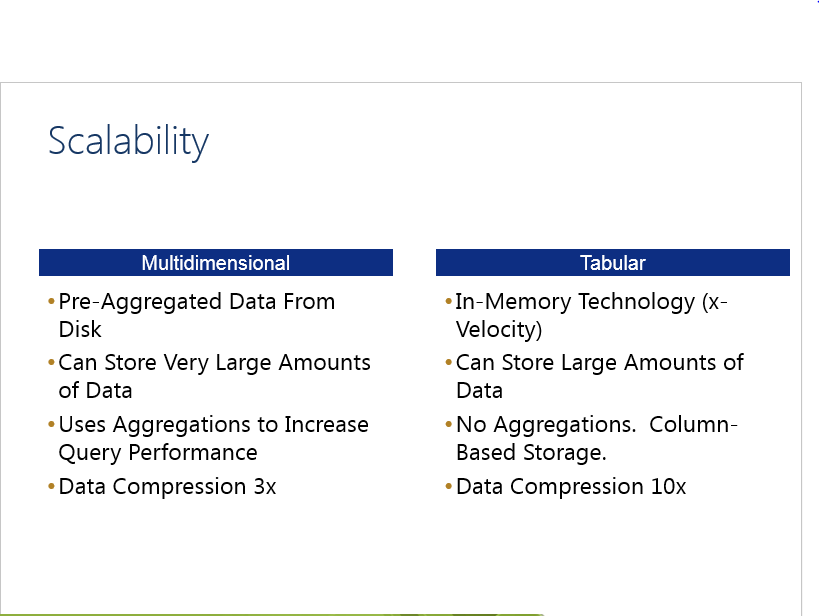
SSAS Tabular vs. SSAS Multidimensional – Scalability
In Part I of the SSAS Tabular vs. SSAS Multidimensional – Which One Do I Choose? series, we covered the different flavors of analysis.
- Analysis Services Tabular – Tabular models are in-memory databases in Analysis Services. Using compression algorithms and multi-threaded query processing, the xVelocity in-memory analytics engine delivers fast access to tabular model objects and data by client applications such as Excel and Power View.
- Analysis Services Multidimensional – An Analysis Services multidimensional solution uses cubes for analyzing data across multiple dimensions. It includes a query and calculation engine for OLAP data with MOLAP, ROLAP, and HOLAP storage modes.
In comparing and contrasting multidimensional and tabular, multidimensional scales better in terms of the amount of data that it can handle and does handle larger number of users when it is being accessed simultaneously. Tabular on the other hand when you have a large number of users requesting data from a model, memory usage will climb accordingly, but the amount required will vary depending on the query itself. From a scalability perspective, the edge goes to Analysis Service multidimensional.
Performance
Multidimensional

How Analysis Service Multidimensional Answers a query.
By reviewing the SSAS internal engine will help us at a high level understand how SSAS responds and ultimately provides data as a result of a query issued against a cube. When a MDX query is issued against a cube, the first stop is the Query Parser. The Query Parser has a XMLA listener which accepts requests, parses the query, and passes it to the Query Processing Engine for query execution.
The Query Processor upon receiving the validated and parsed query from the Query Parser prepares an execution plan which determines how the requested results will be provided from the cube data and the calculations used. The Query Processor caches the the calculation results in the Formula Engine Cache.
The Storage Engine responds to the sub cube data (a subset or logical unit of data for querying, caching and data retrieval) request generated by the Query Processor. It first checks if the requested sub cube data is already available in the Storage Engine cache, if yes then it serves it from there. If not then it checks if the aggregation is already available for the request, if yes then it takes the aggregations from the aggregation store and caches it to the Storage Engine cache and also sends it to Query Processor for serving the request. If not then it grabs the detail data, calculates the required aggregations, caches it to the Storage Engine and then sends it to Query Processor for serving the request.
The easiest way to remember this is:
- the formula engine works out what data is needed for each query and requests it from the storage engine.
- the storage engine handles retrieval of raw data from disk and any aggregations required.
There are several tools that can be used to troubleshoot where a bottleneck may be occurring. This will help you target the right areas for optimization such as the Query Processing Engine or Storage Engine. Tools such as SQL Profiler can be used to perform an OLAP trace which can be used to capture certain events which will tell you the time taken by each of these components.
Additionally, Performance Monitor (perfmon) is a tool that will permit the collection of information using a set of counters to monitor SSAS performance. You can learn more about Performance Monitor here. Another less resource intensive and light weight way of monitoring performance of SSAS is the use of Extended Events.
Tabular

SSAS Tabular Engine
Tabular models can be queried by using both MDX and DAX queries. The diagram explains the underlying query processing architecture of Analysis Services when running in Tabular mode.
DAX queries can reference DAX calculations. These DAX calculation can reside in the model, in the session, or in the DEFINE clause of the DAX query. .
MDX queries can reference MDX calculations, either in the session scope or in the WITH clause of the MDX query. MDX calculations can also reference DAX calculations, but the reverse is not true. MDX queries can directly refer to DAX calculations embedded in the model, and an MDX statement can also define new DAX calculations on the session scope or in the WITH clause of the MDX query. MDX queries against Tabular models are not translated into DAX queries. MDX queries are resolved natively by the MDX formula engine, which can call into the DAX formula engine to resolve DAX measures. The MDX formula engine can also call directly into VertiPaq in cases such as querying dimensions. Excel generates MDX queries to support PivotTables connected to Analysis Services.
DAX calculations in the formula engine can request data from the VertiPaq storage engine as needed. The formula engine allows very rich, expressive calculations. It is single-threaded per query. The storage engine is designed to very efficiently scan compressed data in memory. During a scan, the entire column (all partitions and all segments) are scanned, even in the presence of filters. Given the columnar storage of VertiPaq, this scan is very fast. Because the data is in memory, no I/O is incurred. Unlike the formula engine, a single storage engine query can be answered using multiple threads. One thread is used per segment per column. Some very simple operations such as filters, sums, multiplication, and division can also be pushed down into the storage engine, allowing queries that use these calculations to run multi-threaded.
The formula engine commonly runs several VertiPaq storage engine scans, materializes the results in memory, joins the results together, and applies further calculations. However, if the formula engine determines that a particular calculation can be run more efficiently by doing the calculation as part of the scan, and if the calculation is too complex for the storage engine to compute on its own (for example, an IF function or the LASTDATE function), the VertiPaq storage engine can send a callback to the formula engine. Though the formula engine is single-threaded, it can be called in parallel from the multiple threads servicing a single VertiPaq scan.
Comparing the Multidimensional and Tabular Storage Engines
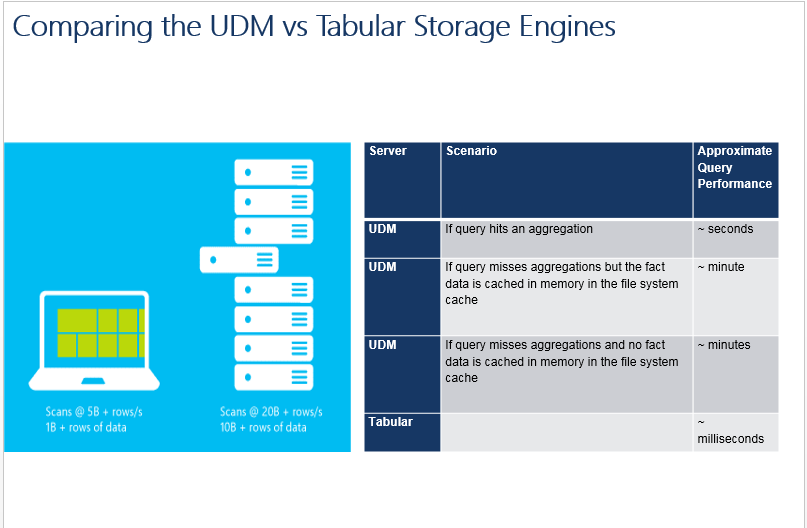
UDM and Tabular Engine Comparison
It is helpful to compare data storage and retrieval in Multidimensional models versus Tabular models. Multidimensional models use row-based storage which is read from disk as needed in queries. Even on wide fact tables, all measures in the fact table are retrieved from storage even if only one measure is needed in a query. Models with hundreds of billions of fact rows are possible with Multidimensional models.
Tabular models use columnar storage which is already loaded into memory when needed by a query. During query execution, only the columns needed in the query are scanned. The VertiPaq engine underlying Tabular models achieves high levels of compression allowing the complete set of model data to be stored in memory, and it achieves blazingly fast data scan rates in memory, providing great query performance.
Tests have shown amazing performance:
- Commodity laptop hardware can service VertiPaq scans at 5 billion rows per second or more and can store in memory billions of rows.
- Commodity server hardware tests have shown VertiPaq scan rates of 20 billion rows per second or more, with the ability to store tens of billions of rows in memory.
To contrast these technologies, try loading a typical two billion row fact table into both a Multidimensional model and a Tabular model. Simple aggregation query performance tests would show results in the following order of magnitude:
- The multidimensional model query performance on large models is highly dependent on whether the administrator has anticipated query patterns and built aggregations.
- In contrast, Tabular model query performance requires no aggregations built during processing time in order to achieve great query performance.
Of course not every query achieves such optimal performance, and to work towards determining the bottleneck for poorly performing queries and applying the appropriate fixes.
Aggregate vs. Detail Data
 While both technologies have the potential to be very fast as far as query results go. I believe to determine the appropriate solution you have to understand what kind of reports are your users actually using.
While both technologies have the potential to be very fast as far as query results go. I believe to determine the appropriate solution you have to understand what kind of reports are your users actually using.
Aggregate Data
Do we typically only need high level reporting on mostly aggregated data? If that is the case, then its very possible to get exceptional queries using a MOLAP solution. With multidimensional cubes, we also have the option to create predesigned aggregations. These predesigned aggregations are basically copies of our fact data files with the same data, except with data at a higher level. These aggregations can be used to greatly increase the performance of our aggregated queries.
Aggregate level reports pointed at multidimensional cubes can also be optimized by using cache warming, which is executing a user’s queries in order to warm the cache for the particular user before the user’s reports are run. Cache warming in addition to aggregations are all really good ways to improve multidimensional query performance.
Aggregate level reports against a Tabular data source are of course going to be very fast, but the difference between a Multidimensional solution and a Tabular solution using an aggregate level report as the comparison is going to be less pronounced because the strength of the Multidimensional solution is reporting at the aggregate level.
Detail Data
But if we require a lot of detail level reporting using very granular reports that are looking at individual sales orders or individual customer orders, we may want to give Tabular some extra consideration. Detail level reports against a Tabular data source are going to be very fast due to the in-memory storage of the data.
Detail level reports against a Multidimensional data source could be significantly slower than the same report against a Tabular data source for a variety of reasons such as the design of the cube, calculations, aggregations, hardware, etc, but generally speaking, detail level reports against a Tabular data source are going to be faster than the same report against a Multidimensional solution.
From a performance perspective, the edge goes to SSAS Tabular.
Conclusion
It is important to take the time and consideration to determine what kind of scalability and performance is absolutely necessary for your SSAS solutions. Stay tuned for upcoming posts exploring time to develop, complex business problems and learning curve considerations for SSAS Tabluar vs Multidimensional.






-1.png)
Leave a comment