


 There are many benefits of partitioning large tables. You can speed up loading and archiving of data, you can perform maintenance operations on individual partitions instead of the whole table, and you may be able to improve query performance. However, implementing table partitioning is not a trivial task and you need a good understanding of how it works to implement and use it correctly.Table Partitioning is an Enterprise Edition feature only.
There are many benefits of partitioning large tables. You can speed up loading and archiving of data, you can perform maintenance operations on individual partitions instead of the whole table, and you may be able to improve query performance. However, implementing table partitioning is not a trivial task and you need a good understanding of how it works to implement and use it correctly.Table Partitioning is an Enterprise Edition feature only.
Being a business intelligence and data warehouse developer, not a DBA, it took me a while to understand table partitioning. I had to read a lot, get plenty of hands-on experience and make some mistakes along the way. (The illustration to the left is my Table Partitioning Cheat Sheet.) One of my favorite ways to learn something is to figure out how to explain it to others. I wanted to follow that up with focused blog posts that included answers to questions I received during the webinar. This post covers the basics of partitioned tables, partition columns, partition functions and partition schemes.
What is Table Partitioning?
 Table partitioning is a way to divide a large table into smaller, more manageable parts without having to create separate tables for each part. Data in a partitioned table is physically stored in groups of rows called partitions and each partition can be accessed and maintained separately. Partitioning is not visible to end users, a partitioned table behaves like one logical table when queried.
Table partitioning is a way to divide a large table into smaller, more manageable parts without having to create separate tables for each part. Data in a partitioned table is physically stored in groups of rows called partitions and each partition can be accessed and maintained separately. Partitioning is not visible to end users, a partitioned table behaves like one logical table when queried.
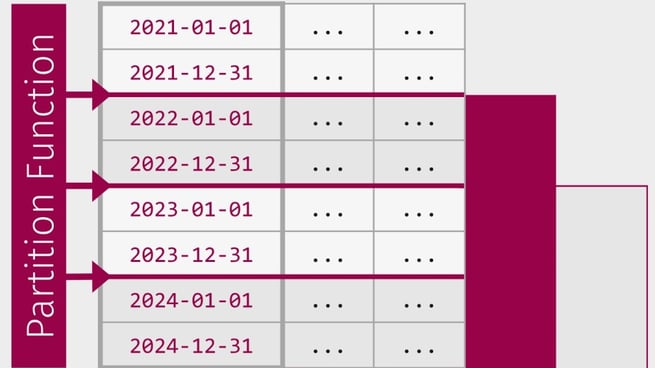
This example illustration is used throughout this blog post to explain basic concepts. The table contains data from every day in 2012, 2013, 2014 and 2015, and there is one partition per year. To simplify the example, only the first and last day in each year is shown.
An alternative to partitioned tables (for those who don’t have Enterprise Edition) is to create separate tables for each group of rows, union the tables in a view and then query the view instead of the tables. This is called a partitioned view. (Partitioned views are not covered in this blog post.)
What is a Partition Column?
 Data in a partitioned table is partitioned based on a single column, the partition column, often called the partition key. Only one column can be used as the partition column, but it is possible to use a computed column.
Data in a partitioned table is partitioned based on a single column, the partition column, often called the partition key. Only one column can be used as the partition column, but it is possible to use a computed column.
In the example illustration the date column is used as the partition column. SQL Server places rows in the correct partition based on the values in the date column. All rows with dates before or in 2012 are placed in the first partition, all rows with dates in 2013 are placed in the second partition, all rows with dates in 2014 are placed in the third partition, and all rows with dates in 2015 or after are placed in the fourth partition. If the partition column value is NULL, the rows are placed in the first partition.
It is important to select a partition column that is almost always used as a filter in queries. When the partition column is used as a filter in queries, SQL Server can access only the relevant partitions. This is called partition elimination and can greatly improve performance when querying large tables.
What is a Partition Function?
 The partition function defines how to partition data based on the partition column. The partition function does not explicitly define the partitions and which rows are placed in each partition. Instead, the partition function specifies boundary values, the points between partitions. The total number of partitions is always the total number of boundary values + 1.
The partition function defines how to partition data based on the partition column. The partition function does not explicitly define the partitions and which rows are placed in each partition. Instead, the partition function specifies boundary values, the points between partitions. The total number of partitions is always the total number of boundary values + 1.
In the example illustration there are three boundary values. The first boundary value is between 2012 and 2013, the second boundary value is between 2013 and 2014, and the third boundary value is between 2014 and 2015. The three boundary values create four partitions. (The first partition also includes all rows with dates before 2012 and the last partition also includes all rows after 2015, but the example is kept simple with only four years for now.)
But what are the actual boundary values used in the example? How do you know which date values are the points between two years? Is it December 31st or January 1st? The answer is that it can actually be either December 31st or January 1st, it depends on whether you use a range left or a range right partition function.
RANGE LEFT AND RANGE RIGHT
Partition functions are created as either range left or range right to specify whether the boundary values belong to their left or right partitions:
• Range left means that the actual boundary value belongs to its left partition, it is the last value in the left partition.
• Range right means that the actual boundary value belongs to its right partition, it is the first value in the right partition.
Left and right partitions make more sense if the table is rotated:
 →
→  →
→ 
RANGE LEFT AND RANGE RIGHT USING DATES
The first boundary value is between 2012 and 2013. This can be created in two ways, either by specifying a range left partition function with December 31st as the boundary value, or as a range right partition function with January 1st as the boundary value:
 →
→  →
→ 
Partition functions are created as either range left or range right, it is not possible to combine both in the same partition function. In a range left partition function, all boundary values are upper boundaries, they are the last values in the partitions. If you partition by year, you use December 31st. If you partition by month, you use January 31st, February 28th / 29th, March 31st, April 30th and so on. In a range right partition function, all boundary values are lower boundaries, they are the first values in the partitions. If you partition by year, you use January 1st. If you partition by month, you use January 1st, February 1st, March 1st, April 1st and so on:
 →
→ 
RANGE LEFT AND RANGE RIGHT USING THE WRONG DATES
If the wrong dates are used as boundary values, the partitions incorrectly span two time periods:
 →
→ 
What is a Partition Scheme?
 The partition scheme maps the logical partitions to physical filegroups. It is possible to map each partition to its own filegroup or all partitions to one filegroup.
The partition scheme maps the logical partitions to physical filegroups. It is possible to map each partition to its own filegroup or all partitions to one filegroup.
A filegroup contains one or more data files that can be spread on one or more disks. Filegroups can be set to read-only, and filegroups can be backed up and restored individually. There are many benefits of mapping each partition to its own filegroup. Less frequently accessed data can be placed on slower disks and more frequently accessed data can be placed on faster disks. Historical, unchanging data can be set to read-only and then be excluded from regular backups. If data needs to be restored it is possible to restore the partitions with the most critical data first.
How do I create a Partitioned Table?
The following script (for SQL Server 2012 and higher) first creates a tally table helper function created by Itzik Ben-Gan that is used to insert test data. The script then creates a partition function, a partition scheme and a partitioned table. (It is important to notice that this script is meant to demonstrate the basic concepts of table partitioning, it does not create any indexes or constraints and it maps all partitions to the [PRIMARY] filegroup. This script is not meant to be used in a real-world project.) Finally it inserts test data and shows information about the partitioned table.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
|
/* --------------------------------------------------
-- Create helper function GetNums by Itzik Ben-Gan
-- http://sqlmag.com/sql-server/virtual-auxiliary-table-numbers
-- GetNums is used to insert test data
-------------------------------------------------- */
-- Drop helper function if it already exists
IF OBJECT_ID('dbo.GetNums') IS NOT NULL
DROP FUNCTION dbo.GetNums;
GO
-- Create helper function
CREATE FUNCTION dbo.GetNums(@n AS BIGINT) RETURNS TABLE AS RETURN
WITH
L0 AS(SELECT 1 AS c UNION ALL SELECT 1),
L1 AS(SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS(SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS(SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS(SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS(SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS(SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
SELECT TOP (@n) n FROM Nums ORDER BY n;
GO
/* ------------------------------------------------------------
-- Create example Partitioned Table (Heap)
-- The Partition Column is a DATE column
-- The Partition Function is RANGE RIGHT
-- The Partition Scheme maps all partitions to [PRIMARY]
------------------------------------------------------------ */
-- Drop objects if they already exist
IF EXISTS (SELECT * FROM sys.tables WHERE name = N'SalesRight')
DROP TABLE dbo.SalesRight;
IF EXISTS (SELECT * FROM sys.partition_schemes WHERE name = N'psSalesRight')
DROP PARTITION SCHEME psSalesRight;
IF EXISTS (SELECT * FROM sys.partition_functions WHERE name = N'pfSalesRight')
DROP PARTITION FUNCTION pfSalesRight;
-- Create the Partition Function
CREATE PARTITION FUNCTION pfSalesRight (DATE)
AS RANGE RIGHT FOR VALUES
('2013-01-01', '2014-01-01', '2015-01-01');
-- Create the Partition Scheme
CREATE PARTITION SCHEME psSalesRight
AS PARTITION pfSalesRight
ALL TO ([Primary]);
-- Create the Partitioned Table (Heap) on the Partition Scheme
CREATE TABLE dbo.SalesRight (
SalesDate DATE,
Quantity INT
) ON psSalesRight(SalesDate);
-- Insert test data
INSERT INTO dbo.SalesRight(SalesDate, Quantity)
SELECT DATEADD(DAY,dates.n-1,'2012-01-01') AS SalesDate, qty.n AS Quantity
FROM dbo.GetNums(DATEDIFF(DD,'2012-01-01','2016-01-01')) dates
CROSS APPLY dbo.GetNums(1000) AS qty;
-- View Partitioned Table information
SELECT
OBJECT_SCHEMA_NAME(pstats.object_id) AS SchemaName
,OBJECT_NAME(pstats.object_id) AS TableName
,ps.name AS PartitionSchemeName
,ds.name AS PartitionFilegroupName
,pf.name AS PartitionFunctionName
,CASE pf.boundary_value_on_right WHEN 0 THEN 'Range Left' ELSE 'Range Right' END AS PartitionFunctionRange
,CASE pf.boundary_value_on_right WHEN 0 THEN 'Upper Boundary' ELSE 'Lower Boundary' END AS PartitionBoundary
,prv.value AS PartitionBoundaryValue
,c.name AS PartitionKey
,CASE
WHEN pf.boundary_value_on_right = 0
THEN c.name + ' > ' + CAST(ISNULL(LAG(prv.value) OVER(PARTITION BY pstats.object_id ORDER BY pstats.object_id, pstats.partition_number), 'Infinity') AS VARCHAR(100)) + ' and ' + c.name + ' <= ' + CAST(ISNULL(prv.value, 'Infinity') AS VARCHAR(100))
ELSE c.name + ' >= ' + CAST(ISNULL(prv.value, 'Infinity') AS VARCHAR(100)) + ' and ' + c.name + ' < ' + CAST(ISNULL(LEAD(prv.value) OVER(PARTITION BY pstats.object_id ORDER BY pstats.object_id, pstats.partition_number), 'Infinity') AS VARCHAR(100))
END AS PartitionRange
,pstats.partition_number AS PartitionNumber
,pstats.row_count AS PartitionRowCount
,p.data_compression_desc AS DataCompression
FROM sys.dm_db_partition_stats AS pstats
INNER JOIN sys.partitions AS p ON pstats.partition_id = p.partition_id
INNER JOIN sys.destination_data_spaces AS dds ON pstats.partition_number = dds.destination_id
INNER JOIN sys.data_spaces AS ds ON dds.data_space_id = ds.data_space_id
INNER JOIN sys.partition_schemes AS ps ON dds.partition_scheme_id = ps.data_space_id
INNER JOIN sys.partition_functions AS pf ON ps.function_id = pf.function_id
INNER JOIN sys.indexes AS i ON pstats.object_id = i.object_id AND pstats.index_id = i.index_id AND dds.partition_scheme_id = i.data_space_id AND i.type <= 1 /* Heap or Clustered Index */
INNER JOIN sys.index_columns AS ic ON i.index_id = ic.index_id AND i.object_id = ic.object_id AND ic.partition_ordinal >= 0
INNER JOIN sys.columns AS c ON pstats.object_id = c.object_id AND ic.column_id = c.column_id
LEFT JOIN sys.partition_range_values AS prv ON pf.function_id = prv.function_id AND pstats.partition_number = (CASE pf.boundary_value_on_right WHEN 0 THEN prv.boundary_id ELSE (prv.boundary_id+1) END)
WHERE pstats.object_id = OBJECT_ID('dbo.SalesRight')
ORDER BY TableName, PartitionNumber;
|
Summary
The partition function defines how to partition a table based on the values in the partition column. The partitioned table is created on the partition scheme that uses the partition function to map the logical partitions to physical filegroups.
If each partition is mapped to a separate filegroup, partitions can be placed on slower or faster disks based on how frequently they are accessed, historical partitions can be set to read-only, and partitions can be backed up and restored individually based on how critical the data is.
This post is the first in a series of Table Partitioning in SQL Server blog posts. It covers the basics of partitioned tables, partition columns, partition functions and partition schemes. Future blog posts in this series will build upon this information and these examples to explain other and more advanced concepts.
Want to learn more from Cathrine? Check out her blog or follow her on Twitter!





-1.png)
Leave a comment