




What do you know about Azure Databricks? If you’re unsure of what it is and how it’s used, I’m here today to clear that up with a high-level overview of the tool. Databricks is great for data engineering and data analytics.
Azure Databricks is an analytics engine for big data processing with built in modules for streaming, SQL, machine learning and graph processing and is based on Apache Spark. Spark is a lightning-fast unified analytics engine for big data and machine learning; Databricks makes it possible for organizations to quickly get started with Apache Spark.
Databricks is optimized for the cloud with in-memory, tightly coupled compute and data nodes, giving you near infinite scale. It’s also lightning fast since the data and computing are interconnected in the system (known as high coupling) and distributed across nodes. How fast? You can get data sets that range in the billions in seconds, so incredibly fast!
There are no predetermined structures, so it gives you flexibility as to how you ingest, shape, model and analyze the data. The types of applications that are used with Databricks are many including: ETL, predictive analytics, machine learning, SQL queries, visualizations, text mining and text processing, real-time event processing, graph applications, pattern recognition and recommendation engines.
The fact that it’s good for data engineering and analytics makes it extremely versatile and good for IOT data, streaming data, publications and subscriptions, notifications and alerting. A couple things it is not - it’s not an OLTP engine and it’s not good for data that’s updated in place.
You can have multiple data storage types for input and output; you can have local HDFS, Azure Blob Storage, Azure Data Lake (Gen1 and 2), SQL and No SQL type databases as well such as Cosmos.
Here’s the big question – how do you use Azure Databricks? Databricks uses a batching and micro batching approach, giving you the flexibility to use multiple languages such as Python, Java, SQL, R, C# and PowerShell for scripting and querying. Azure Databricks is tightly fitted and integrated within the Azure ecosphere, making it an important piece to utilize as you’re working in Azure.
Databricks allows for data science and data engineering combined with AI. The image below shows where Databricks fits in:
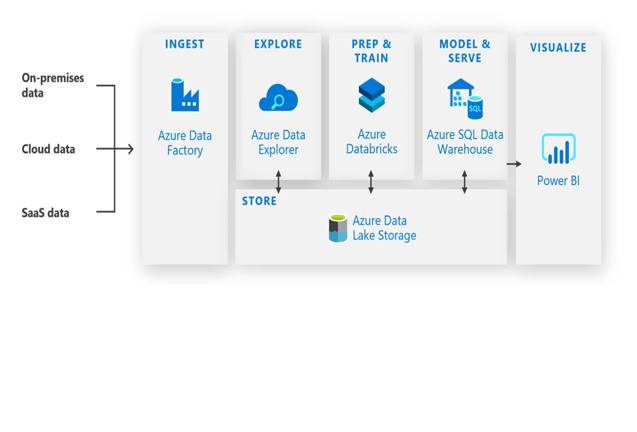 As you can see, you ingest your data using Azure Data Factory, then it’s stored, and you can explore it with tools like Azure Data Explorer. Where Databricks comes into play is you can mash up all these different data types and then lay AI on top of them, then ingest them into a structured data warehouse and do your visualization on top of that.
As you can see, you ingest your data using Azure Data Factory, then it’s stored, and you can explore it with tools like Azure Data Explorer. Where Databricks comes into play is you can mash up all these different data types and then lay AI on top of them, then ingest them into a structured data warehouse and do your visualization on top of that.
You can get a 30-day free trial of Azure Databricks in the Azure Portal. It spins up easily and there are many references to get you started. I highly suggest you give it a try.
Looking for more about Azure? We've got the conference for you! Azure Data Week is coming to you in October - the only virtual conference 100% dedicated to Azure topics. With 4 jam packed days, eight 1-hour sessions each day that you can pick and choose from, plus access to all the recordings for one year all for only $49! Click the link below to learn more and register for this incredible event!





-1.png)
Leave a comment