



One of my favorite features (admittedly, there are quite a few) of SQL Server 2016 is PolyBase. It’s a fantastic piece of technology that allows users to near seamlessly tie relational and non-relational data. This feature has been available for Analytics Platform System (APS) and SQL Data Warehouse (SQL DW) for some time, and fortunately, it has finally made its way to SQL Server, thanks to the SQL Server 2016 release.
What is PolyBase?
PolyBase is a technology that accesses and combines both non-relational and relational data, all from within SQL Server.
It allows you to run queries on external data in Hadoop or Azure blob storage. The queries are optimized to push computation to Hadoop.

As previously mentioned, PolyBase is currently utilized by:
- SQL Server 2016
- Azure SQL DW
- Analytics Platform System (APS)
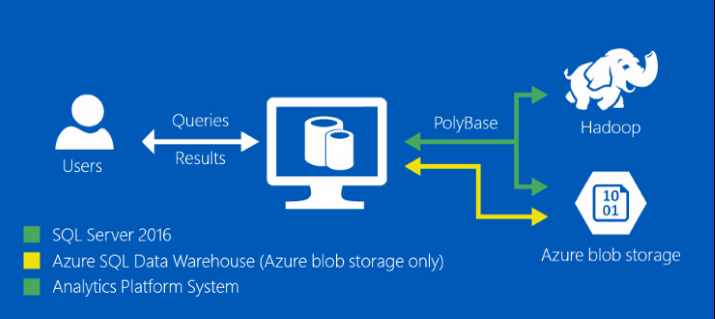
What does this mean? It means that there’s flexibility for an evolving road map, whether it’s on premise (scaling out with APS), or Azure (SQL DW and SQL DB [coming in the near future]). The players change, but the game stays the same. Granted, there are some exceptions, but they should all provide the same functionality soon.
What Can PolyBase Do?
Query data stored in Hadoop. Users are storing data in cost-effective distributed and scalable systems, such as Hadoop. PolyBase makes it easy to query the data by using T-SQL.
- Query relational and non-relational data with T-SQL, which allows
- New business insights across your data lake
- Leveraging existing skill sets and BI tools
- Faster time to insights and simplified ETL process

In the example above, an insurance company could join member information from a data warehouse in SQL Server and join it to vehicle sensor data from Hadoop, creating real-time insurance quotes based on demographic information as well as driving habits.
Query data stored in Azure blob storage. Azure blob storage is a convenient place to store data for use by Azure services. PolyBase makes it easy to access the data by using T-SQL.
Integrate with BI tools. Use PolyBase with Microsoft’s business intelligence and analysis stack, or use any third party tools that is compatible with SQL Server.
Import data from Hadoop or Azure blob storage. Leverage the speed of Microsoft SQL’s columnstore technology and analysis capabilities by importing data from Hadoop or Azure blob storage into relational tables. There is no need for a separate ETL or import tool.
Export data to Hadoop or Azure blob storage. Archive data to Hadoop or Azure blob storage to achieve cost-effective storage and keep it online for easy access.
PolyBase Performance
Personally, one of my main concerns when I heard about this technology was performance. Surely there has to be a huge performance hit on SQL Server, right? The answer is, only if you want/need it to be. It depends on which system demands higher availability and less system impact.
Push computation to Hadoop
The query optimizer makes a cost-based decision to push computation to Hadoop when doing so will improve query performance. It uses statistics on external tables to make the cost-based decision. Pushing computation creates MapReduce jobs and leverages Hadoop’s distributed computational resources. To improve SQL Server query performance, enable pushdown computation on SQL Server by copying the Yarn class path in Hadoop to the SQL Server configuration. Then force the compute to the Hadoop cluster.
Scale Compute Resources
To improve query performance, and similar to scaling out Hadoop to multiple compute nodes, you can use SQL Server PolyBase scale-out groups. This enables parallel data transfer between SQL Server instances and Hadoop nodes, and it adds compute resources for operating on the external data. This allows the ability to scale out as compute requires.

Now that we know how it works at a high level and that we absolutely want to use it, let’s walk through the installation process.
PolyBase Requirements
An instance of SQL Server (64-bit).
- Microsoft .NET Framework 4.5.
- Oracle Java SE RunTime Environment (JRE) version 7.51 or higher (64-bit). Go to Java SE downloads. The installer will fail if JRE is not present. *
- Minimum memory: 4GB
- Minimum hard disk space: 2GB
- TCP/IP connectivity must be enabled. (See Enable or Disable a Server Network Protocol.)
* I always chuckle when I see the Oracle JRE requirement as Microsoft and Oracle are direct competitors
An external data source, one of the following:
- Hadoop clusterHortonworks HDP 1.3 on Linux/Windows Server
- Hortonworks HDP 2.0 – 2.3 on Linux/Windows Server
- Cloudera CDH 4.3 on Linux
- Cloudera CDH 5.1 – 5.5 on Linux
- Azure blob storage account
- Azure Data Lake (Not yet, but most likely in the near future as it is HDFS “under the hood”)
PolyBase Configuration
At a high level, you must complete the following all through T-SQL:
- Install PolyBase
a. PolyBase Data Movement Service
b. PolyBase Engine - Configure SQL Server and enable the option
- Configure Pushdown (Not Required)
- Scale Out (Not Required)
- Create Master Key and Scoped Credential
- Create external data source
- Create external file format
- Create external table
Enable PolyBase
First see if it is enabled:
SELECT SERVERPROPERTY (‘IsPolybaseInstalled’)
If not, enable it with the appropriate connection type. Remember to execute the RECONFIGURE command so it takes effect the next time the service is restarted.
— 5 denotes the connection type
EXEC sp_configure ‘hadoop connectivity’, 5;RECONFIGURE;
The connection types are as follows:
Option 0: Disable Hadoop connectivity
Option 1: Hortonworks HDP 1.3 on Windows Server
Option 1: Azure blob storage (WASB[S])
Option 2: Hortonworks HDP 1.3 on Linux
Option 3: Cloudera CDH 4.3 on Linux
Option 4: Hortonworks HDP 2.0 on Windows Server
Option 4: Azure blob storage (WASB[S])
Option 5: Hortonworks HDP 2.0 on Linux
Option 6: Cloudera 5.1, 5.2, 5.3, 5.4, and 5.5 on Linux
Option 7: Hortonworks 2.1, 2.2, and 2.3 on Linux
Option 7: Hortonworks 2.1, 2.2, and 2.3 on Windows Server
Option 7: Azure blob storage (WASB[S])
* I’m not sure why there are multiple options for Azure Blob Storage (options 1, 4 & 7). Maybe someone can tell me?
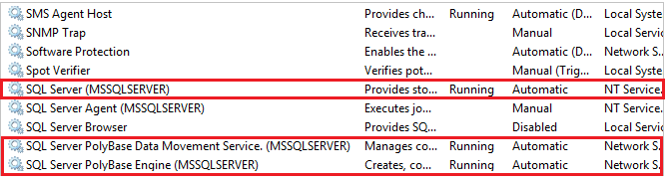
Then restart:
- SQL Server
- PolyBase Data Movement Service
- PolyBase Engine
Enable Pushdown
As previously mentioned, to improve query performance, enable pushdown computation to a Hadoop cluster:
1. Find the file yarn-site.xml in the installation path of SQL Server. Typically, the path is:
C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Binn\Polybase\Hadoop\conf\
2. On the Hadoop machine, find the analogous file in the Hadoop configuration directory. In the file, find and copy the value of the configuration key yarn.application.classpath.
3. On the SQL Server machine, in the yarn.site.xml file, find the yarn.application.classpath property. Paste the value from the Hadoop machine into the value element.
Scale Out PolyBase
The PolyBase group feature allows you to create a cluster of SQL Server instances to process large data sets from external data sources in a scale-out fashion for better query performance.
- Install SQL Server with PolyBase on multiple machines.
- Select one SQL Server as head node.
- Add other instances as compute nodes by running sp_polybase_join_group.
— Enter head node details:
— head node machine name, head node dms control channel port, head node sql server name
EXEC sp_polybase_join_group ‘PQTH4A-CMP01’, 16450, ‘MSSQLSERVER’;
4. Restart the PolyBase Data Movement Service on the compute nodes.
Create Master Key and Scoped Credential
In previous versions of SQL Server 2016 (CTP through RC), this was done using a configuration file. This is now in the much more friendly T-SQL context that most of us are familiar with. This is enabled at the database level. If a master key has already been created, this step can be skipped, however it is required to encrypt the credential secret.
— Create a master key on the database.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = ‘Pr@gm@t1cW0rk$’;— IDENTITY: the user name
— SECRET: the password
CREATE DATABASE SCOPED CREDENTIAL HDPUser WITH IDENTITY = ‘hue’, Secret = ”;
Create the External Data Source
Provide and alias for your external data source and point it to your Hadoop cluster and port, using the scoped credential. When architecting your Hadoop and SQL Server solution, remember that because the scope credential and external data source are at the database level, there can be multiple users, with multiple credentials with varying levels of access within Hadoop. This can all be used collectively as a security model.
CREATE EXTERNAL DATA SOURCE [HDP2] WITH
(TYPE = HADOOP,
LOCATION = N’hdfs://pwpchadoop.cloudapp.net:8020′,
CREDENTIAL = HDPUser);
Create the External File Format
When creating the external file format, it’s important to specify the obvious settings of the format type and field delimiter, but equally important is the date format. If the format does not match the source system, the conversion will fail and an error will occur when attempting to select the data from the Hadoop cluster.
CREATE EXTERNAL FILE FORMAT TSV WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (
FIELD_TERMINATOR = ‘\t’,
DATE_FORMAT = ‘MM/dd/yyyy’))
Supported file types for external files are:
- Delimited text
- Hive RCFile
- Hive ORC
- Parquet
Reference https://msdn.microsoft.com/en-us/library/dn935026.aspx for additional details, particularly for the date format.
Create External Table
Last, but not least, create the external table. The order and datatypes are critical. If columns are specified in an order that does not match the Hadoop cluster, the implicit type cast may result in an error at best, or the wrong data in the wrong field at the worst. The type casting from Hadoop to SQL Server is implicit, so if the SQL external table has an int, but the Hadoop cluster has a float, the cast will be successful, but precision will be lost. Similarly, if an integer is specified, but the source is a string (ex. ‘FY2009’), an error will occur. Match numbers to numbers (at the right precision), dates to dates, strings to strings, etc.
Specify the previously aliased datasource and file format, as well as the physical location of the file. Similar to Hive, you may specify a directory with multiple files provided they all share the same structure and metadata.
CREATE EXTERNAL TABLE HDP_FactInternetSales
([ProductKey] [int],
[OrderDateKey] [int],
[DueDateKey] [int],
[ShipDateKey] [int],
[CustomerKey] [int],
…)WITH
(LOCATION = ‘/apps/hive/warehouse/factinternetsales’,
DATA_SOURCE = HDP2,
FILE_FORMAT = TSV,
REJECT_TYPE = value,
REJECT_VALUE=0)
Using PolyBase
Now that everything’s all set up, it’s time to start playing around.
Insert to SQL Server from Hadoop
SELECT Insured_Customers.FirstName, Insured_Customers.LastName,
Insured_Customers.YearlyIncome, Insured_Customers.MaritalStatus
INTO Fast_Customers from Insured_Customers
INNER JOIN
(SELECT * FROM CarSensor_Data where Speed > 35) AS SensorD
ON Insured_Customers.CustomerKey = SensorD.CustomerKey
In the example above, the external CarSensor_Data table from Hadoop is being used as a filter to populate the SQL Server table Fast_Customers, where the external driving speed is greater than 35.
Insert to Hadoop from SQL Server
First, ensure that the setting is enabled on the server to export from PolyBase to the Hadoop cluster (and restart the service).
sp_configure ‘allow polybase export’, 1;
RECONFIGURE;
Then create the external data in Hadoop, specifying the file name and location, data source and file format.
CREATE EXTERNAL TABLE [dbo].[FastCustomers2009] (
[FirstName] char(25) NOT NULL,
[LastName] char(25) NOT NULL,
[YearlyIncome] float NULL,
[MaritalStatus] char(1) NOT NULL)
WITH (LOCATION=’/old_data/2009/customerdata.tbl’,
DATA_SOURCE = HadoopHDP2,
FILE_FORMAT = TextFileFormat,
REJECT_TYPE = VALUE,
REJECT_VALUE = 0);
Once the table is created, the data can be pushed from SQL Server to Hadoop.
SELECT *
INTO [dbo].[FastCustomers2009]
FROM Fast_Customers
Ad-Hoc Queries
To force external compute down to the Hadoop cluster, or disable it, use the OPTION clause.
SELECT DISTINCT Insured_Customers.FirstName, Insured_Customers.LastName, Insured_Customers.YearlyIncome, CarSensor_Data.Speed
FROM Insured_Customers, CarSensor_Data
WHERE Insured_Customers.CustomerKey = CarSensor_Data.CustomerKey and
CarSensor_Data.Speed > 35
ORDER BY CarSensor_Data.Speed DESC
OPTION (FORCE EXTERNALPUSHDOWN);
— or OPTION (DISABLE EXTERNALPUSHDOWN)
Pushdown
Use pushdown for selecting a subset of columns.
Use predicate pushdown to improve performance for a query that selects a subset of columns from an external table. Predicate pushdowns will be the lease compute intense comparisons Hadoop can do.
In this query, SQL Server initiates a map-reduce job to pre-process the Hadoop delimited-text file so that only the data for the two columns,customer.name and customer.zip_code, will be copied to SQL Server.
SELECT customer.name, customer.zip_code
FROM customer
WHERE customer.account_balance < 200000
For example, the predicate in the where clause will be extremely fast because it is a predicate clause.
Also, use pushdown for basic expressions and operators. SQL Server allows the following basic expressions and operators for predicate pushdown.
- Binary comparison operators ( <, >, =, !=, <>, >=, <= ) for numeric, date, and time values
- Arithmetic operators ( +, -, *, /, % )
- Logical operators (AND, OR)
- Unary operators (NOT, IS NULL, IS NOT NULL)
PolyBase Performance and Troubleshooting
PolyBase comes with a set of DMVs which come in extremely handy when performance issues or errors occur. Reference https://msdn.microsoft.com/en-us/library/mt652314.aspx for the complete list, however the following are a great start.
Find the longest running query:
SELECT execution_id, st.text, dr.total_elapsed_time
FROM sys.dm_exec_distributed_requests dr
cross apply sys.dm_exec_sql_text(sql_handle) st
ORDER BY total_elapsed_time DESC;
Find the longest running step of the distributed query plan:
SELECT execution_id, step_index, operation_type, distribution_type, location_type, status, total_elapsed_time, command
FROM sys.dm_exec_distributed_request_steps
WHERE execution_id = ‘QID4547’
ORDER BY total_elapsed_time DESC;
Find the execution progress of a SQL step:
SELECT execution_id, step_index, distribution_id, status, total_elapsed_time, row_count, command
FROM sys.dm_exec_distributed_sql_requests
WHERE execution_id = ‘QID4547’ and step_index = 1;
Find the slowest part of the external compute step:
SELECT execution_id, step_index, dms_step_index, compute_node_id, type, input_name, length, total_elapsed_time, status
FROM sys.dm_exec_external_work
WHERE execution_id = ‘QID4547’ and step_index = 7
ORDER BY total_elapsed_time DESC;
When all fails, dig in and take a look at the execution plan in SSMS. It will provide more specifics, such as estimated degree of parallelism, etc.

Last but not Least, Have Fun and Play!
For the first time, SQL Server 2016 Developer is free to all users and comes with the exact same features as the enterprise version. So any and all developers can install locally and have all features readily available to them. Another free tool, SQL Server Data Tools for Visual Studio 2015, allow any and all developers to get up and running and have a little fun.
- SQL Server 2016 Developer Edition
https://www.microsoft.com/en-us/server-cloud/products/sql-server-editions/sql-server-developer.aspx - SQL Server Data Tools For Visual Studio 2015
https://msdn.microsoft.com/en-us/library/mt204009.aspx
Hopefully this was helpful to some. I’m still learning a lot, particularly because this just went RTM a week ago and I was on vacation all last week, but this was a lot of fun to play with and I can’t wait to show everyone more features of the SQL Serer 2016 stack. Take care!






-1.png)
Leave a comment